Abstract
Vision encoders for retrieval are typically trained with class-label supervision: each
training pair reduces to a scalar that uniformly pushes the embedding apart or pulls it together, as if
every visual attribute either differed or matched. A multimodal large language model (MLLM), shown the
same pair, can articulate those attributes and use them to predict whether the images share a class. We
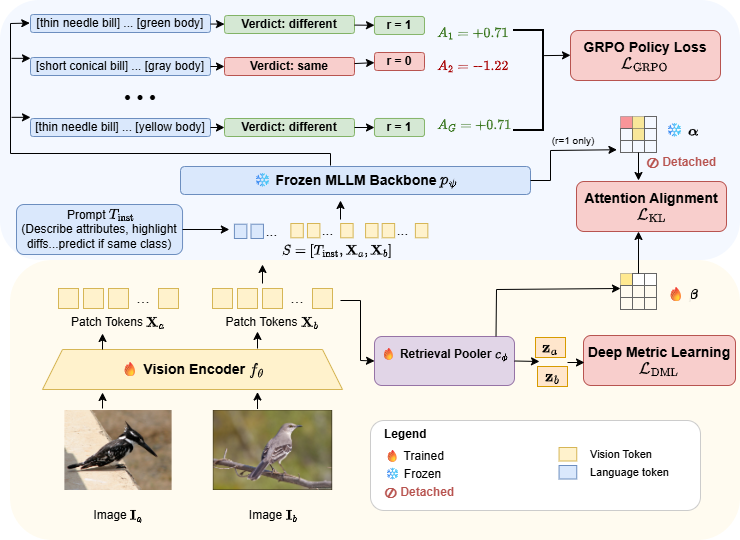
propose SAGA, a framework that turns this language-grounded, attribute-aware perception into a
training signal for the encoder itself. Specifically, we use Group Relative Policy Optimization (GRPO) to
reward the MLLM for correct predictions on the vision encoder's tokens. Since correct predictions require
those tokens to expose the specific attributes that differ or match between the pair, the gradient
pushes the encoder to encode them, replacing the uniform pair-level scalar with attribute-resolved
supervision. An auxiliary attention-distillation loss anchors the encoder's embedding to tokens the MLLM
attended to, and a standard metric-learning loss shapes the embedding geometry for nearest-neighbour
retrieval. The MLLM is frozen throughout and discarded at inference, matching the deployment cost of a
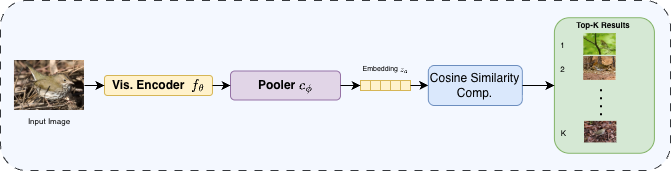
metric-learning baseline. SAGA improves Recall@1 by 3 to 6 points over state-of-the-art baselines on
CUB-200-2011, Cars-196, FGVC-Aircraft, and iNaturalist Aves on zero-shot image retrieval.
TL;DR
SAGA replaces the single scalar of class-label metric learning with attribute-resolved supervision
distilled from a frozen MLLM, training a vision encoder whose embeddings capture the fine-grained
attributes that matter for zero-shot retrieval. The MLLM is discarded at inference, so deployment
costs nothing extra.