|
Shubhang Bhatnagar Hi, I am Shubhang Bhatnagar, a fifth year PhD student in the Computer Vision and Robotics Laboratory at the University of Illinois Urbana-Champaign. I am grateful to be advised by Prof. Narendra Ahuja . Broadly, I am interested in computer vision, machine learning and their applications. Currently, my research focuses on Large Multimodal Models (LMMs) and their applications in computer vision. Previously, I completed my Dual degree (B.Tech + M.Tech) in electrical engineering from Indian Institute of Technology, Bombay, where I was awarded the Institute Silver medal for graduating at the top of my batch. I am open to discussion and collaborations, feel free to reach out E-mail / Resume / GitHub / Google Scholar / LinkedIn / Twitter |

|
Research |
|
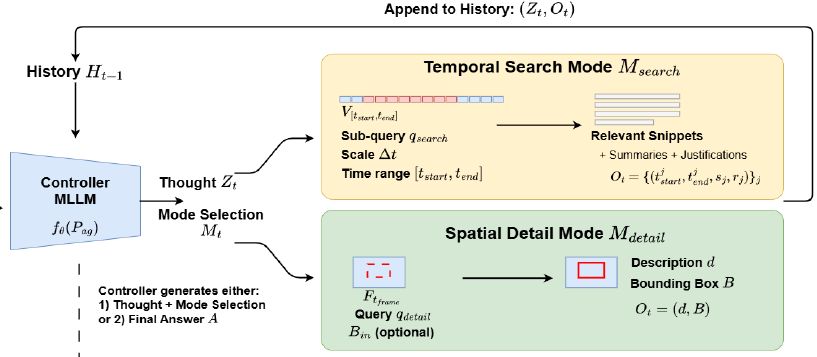
VideoMind: Thinking in Steps for Long Video UnderstandingShubhang Bhatnagar, Renxiong Wang, Kapil Krishnakumar, Adel Ahmadyan, Zhaojiang Lin, Lambert Mathias, Xin Luna Dong, Babak Damavandi, Narendra Ahuja, Seungwhan Moon European Chapter of the Association for Computational Linguistics (EACL), 2026 (Industry, Oral) abstract / project page Multimodal Large Language Models (MLLMs) struggle with Long Video Understanding (LVU) due to their limited context window and the distributed nature of salient information across many redundant frames. To address this, we present VideoMind, a novel training free framework for LVU designed to mimic a human reasoning process. The framework is orchestrated by an MLLM that breaks down a user's query into a series of simpler, actionable sub-queries. For each sub query, the MLLM reconfigures itself by invoking specialized `modes' that are instantiations of the same MLLM, but with appropriately tailored context for the given sub query to extract targeted evidence. After gathering this evidence, the model resumes its role as the orchestrator which evaluates the results and decides if an answer is complete or if it must refine its strategy by engaging further modes with new context. Our specialized operational modes include: 1) a Multi-Scale Temporal Search mode to identify and summarize relevant video sub-snippets at varying time scales, and 2) a Single-Frame Visual Detail mode for precise spatial localization of objects. This dynamic allocation of computation yields state-of-the-art results on the Video-MME, LongVideo, and MLVU benchmarks, achieving 77.6% performance on Video MME using Qwen 2.5 72B (4.8% enhancement) while also yielding a 5% improvement on Llama 4 Scout. |
|
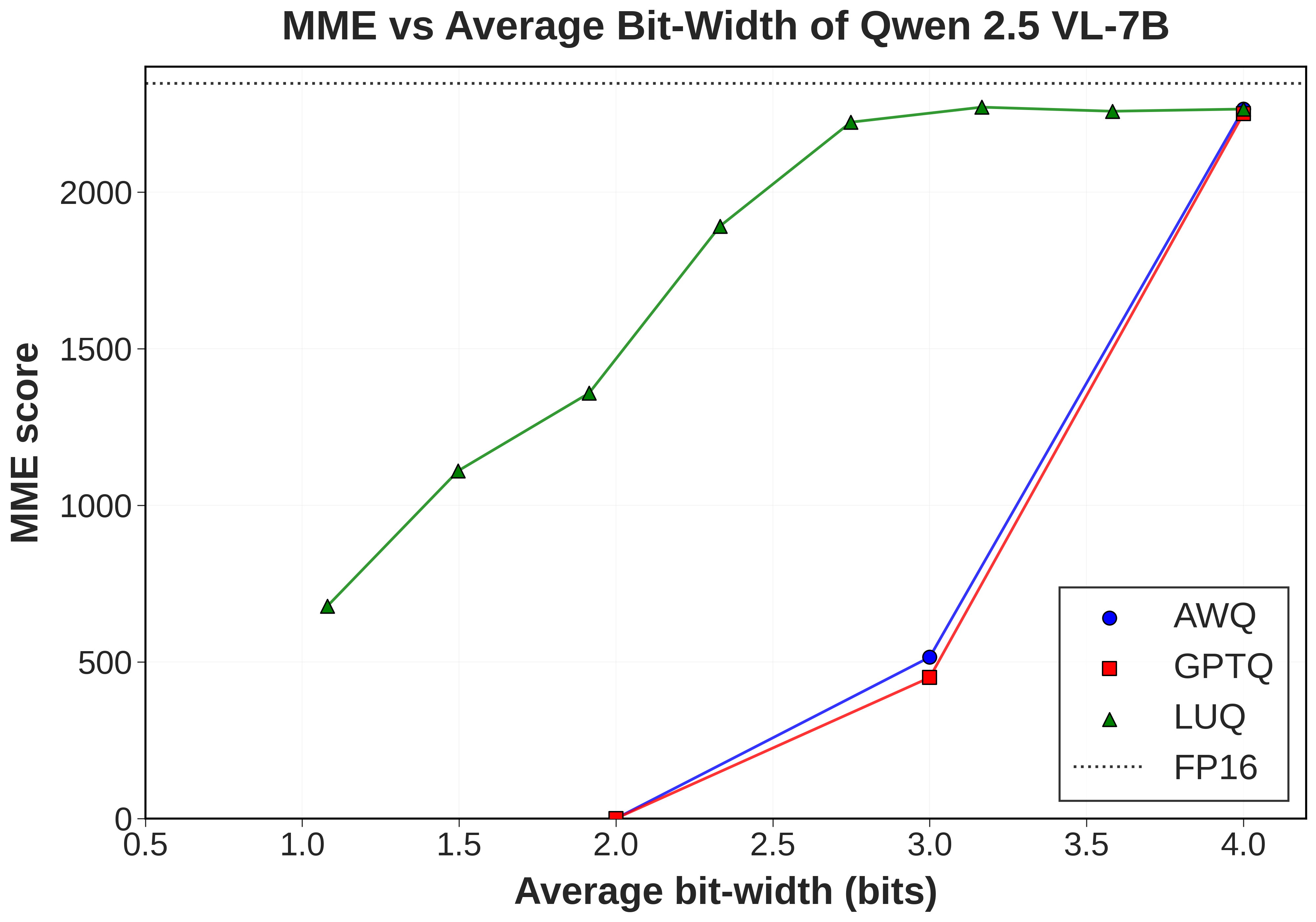
LUQ: Layerwise Ultra-Low Bit Quantization for MLLMsShubhang Bhatnagar, Andy Xu, Kar Han Tan, Narendra Ahuja Under Review abstract / project page / paper Large Language Models (LLMs) with multimodal capabilities have revolutionized vision-language tasks, but their deployment often requires huge memory and computational resources. While post-training quantization (PTQ) has successfully compressed language models to as low as 1-bit precision without significant performance loss, its effectiveness for multimodal LLMs (MLLMs) remains relatively unexplored. In this paper, we present the first study on ultra-low bit (< 4-bit) quantization for multimodal LLMs. Our analysis reveals that multimodal tokens and intermediate layer activations produced by them exhibit significantly higher statistical variance and entropy compared to text tokens, making them less tolerant to ultra-low bit quantization. However, the activation distributions of multimodal tokens varies significantly over different layers, with some layers having lower entropy activation distributions. We empirically show that such layers in these models can better tolerate ultra-low bit quantization. Building on these insights, we propose a novel strategy for MLLM quantization, LUQ: Layerwise Ultra-Low Bit Quantization, which selectively applies ultra-low bit quantization to layers that are more resilient to it. Additionally, we also show that using a mix of multimodal tokens (image and text) for PTQ boosts VQA performance in the ultra-low bit regime. We evaluate our method on LLaVA-1.5 and Qwen-2.5-VL across 9 popular VQA benchmarks. The resulting LUQ models use 40% and 31% less memory than their 4-bit counterparts, respectively, while exhibiting a performance degradation of less than 10% on the MME benchmark. |
|
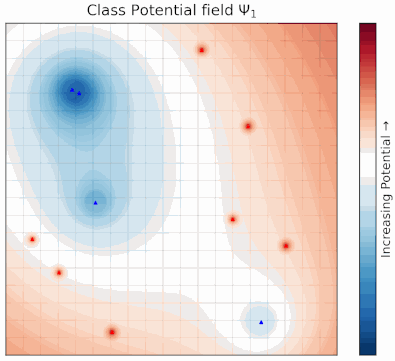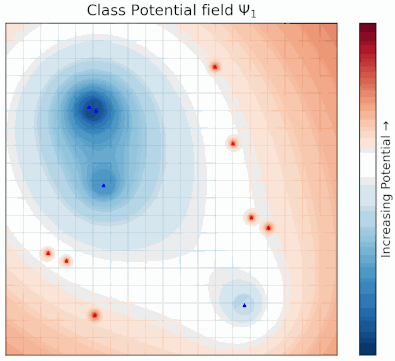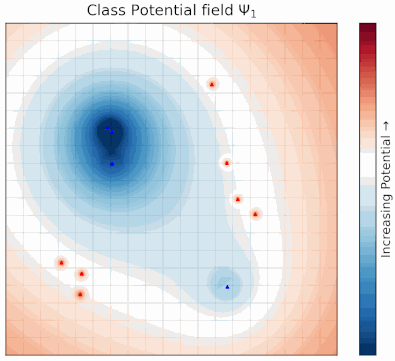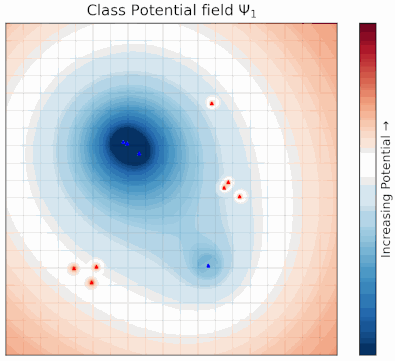
Potential Field Based Deep Metric LearningShubhang Bhatnagar, Narendra Ahuja Computer Vision and Pattern Recognition Conference (CVPR), 2025 abstract / project page / paper Deep metric learning (DML) involves training a network to learn a semantically meaningful representation space. Many current approaches mine n-tuples of examples and model interactions within each tuplets. We present a novel, compositional DML model, inspired by electrostatic fields in physics that, instead of in tuples, represents the influence of each example (embedding) by a continuous potential field, and superposes the fields to obtain their combined global potential field. We use attractive/repulsive potential fields to represent interactions among embeddings from images of the same/different classes. Contrary to typical learning methods, where mutual influence of samples is proportional to their distance, we enforce reduction in such influence with distance, leading to a decaying field. We show that such decay helps improve performance on real world datasets with large intra-class variations and label noise. Like other proxy-based methods, we also use proxies to succinctly represent sub-populations of examples. We evaluate our method on three standard DML benchmarks- Cars-196, CUB-200-2011, and SOP datasets where it outperforms state-of-the-art baselines. |
|
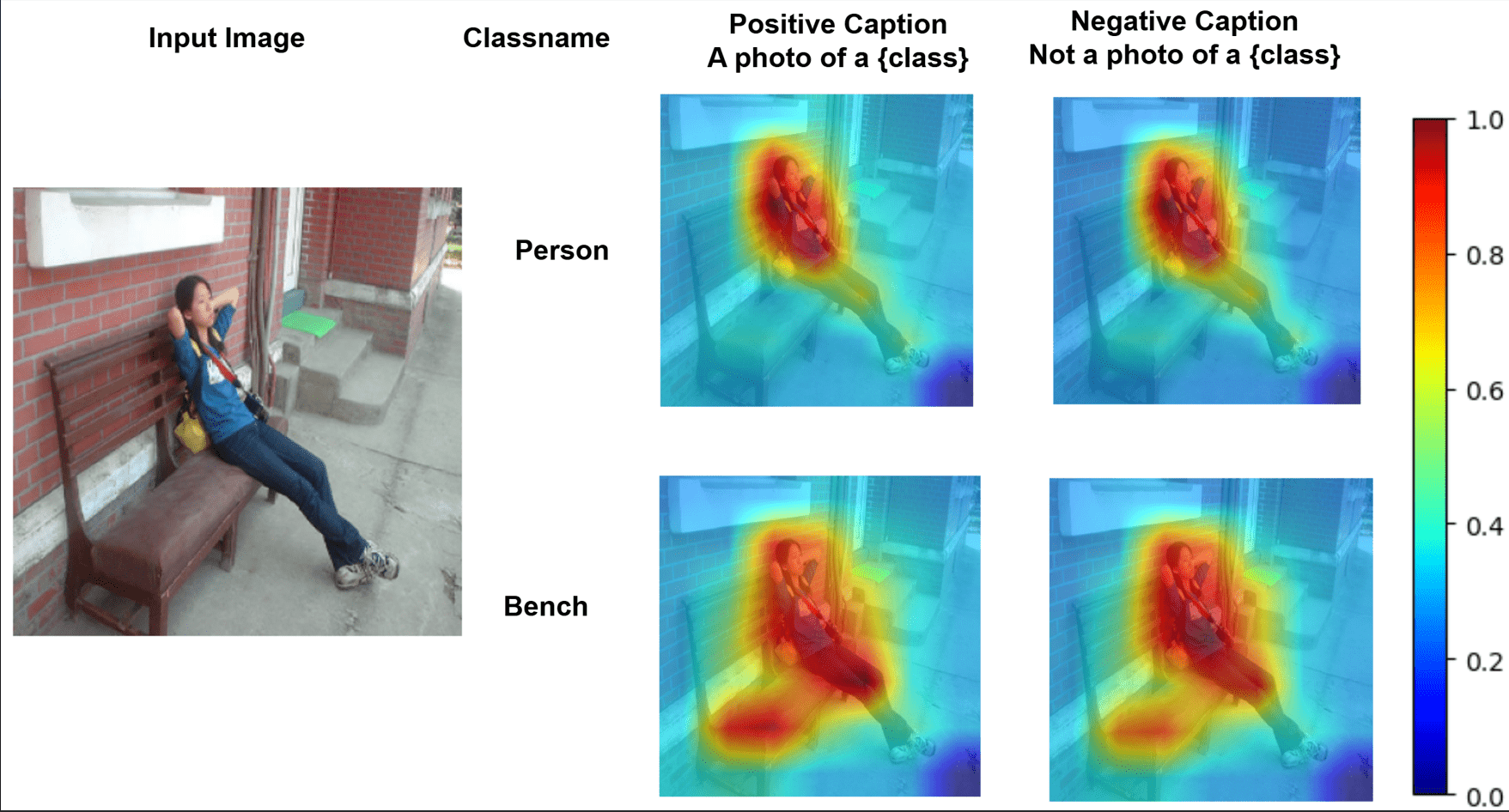
PositiveCoOp: Rethinking Prompting Strategies for Multi-Label Recognition with Partial AnnotationsSamyak Rawlekar,Shubhang Bhatnagar, Narendra Ahuja Winter Conference on Applications of Computer Vision (WACV), 2025 abstract / project page / paper Vision-language models (VLMs) like CLIP have been adapted for Multi-Label Recognition (MLR) with partial annotations by leveraging prompt-learning, where positive and negative prompts are learned for each class to associate their embeddings with class presence or absence in the shared vision-text feature space. While this approach improves MLR performance by relying on VLM priors, we hypothesize that learning negative prompts may be suboptimal, as the datasets used to train VLMs lack image-caption pairs explicitly focusing on class absence. To analyze the impact of positive and negative prompt learning on MLR, we introduce PositiveCoOp and NegativeCoOp, where only one prompt is learned with VLM guidance while the other is replaced by an embedding vector learned directly in the shared feature space without relying on the text encoder. Through empirical analysis, we observe that negative prompts degrade MLR performance, and learning only positive prompts, combined with learned negative embeddings (PositiveCoOp), outperforms dual prompt learning approaches. Moreover, we quantify the performance benefits that prompt-learning offers over a simple vision-features-only baseline, observing that the baseline displays strong performance comparable to dual prompt learning approach (DualCoOp), when the proportion of missing labels is low, while requiring half the training compute and 16 times fewer parameters. |
|
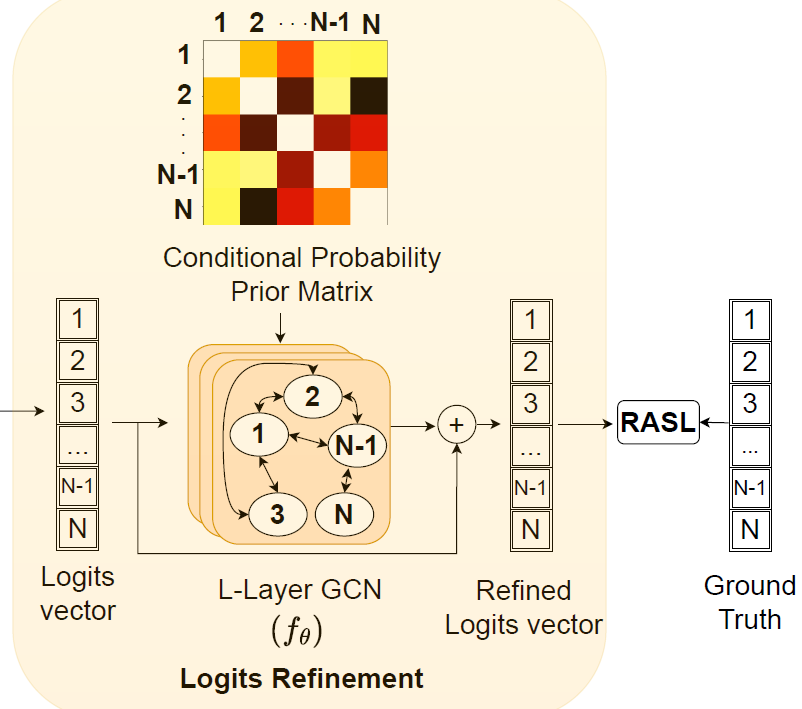
Improving Multi-label Recognition using Class Co-Occurrence ProbabilitiesShubhang Bhatnagar*, Samyak Rawlekar* , Vishnuvardhan Pogunulu Srinivasulu, Narendra Ahuja CVPRw 2024, ICPR 2024 (Oral Top-5%) abstract / project page / paper Multi-label Recognition (MLR) involves the identification of multiple objects within an image. To address the additional complexity of this problem, recent works have leveraged information from vision-language models (VLMs) trained on large text-images datasets for the task. These methods learn an independent classifier for each object (class), overlooking correlations in their occurrences. Such co-occurrences can be captured from the training data as conditional probabilities between a pair of classes. We propose a framework to extend the independent classifiers by incorporating the co-occurrence information for object pairs to improve the performance of independent classifiers. We use a Graph Convolutional Network (GCN) to enforce the conditional probabilities between classes, by refining the initial estimates derived from image and text sources obtained using VLMs. We validate our method on four MLR datasets, where our approach outperforms all state-of-the-art methods. |
|
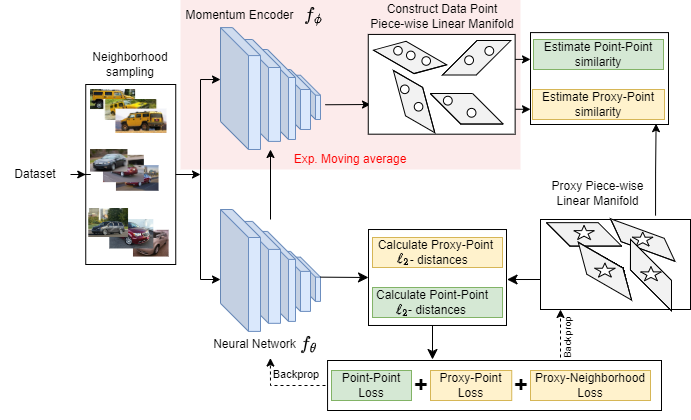
Piecewise-Linear Manifolds for Deep Metric LearningShubhang Bhatnagar, Narendra Ahuja In Proceedings of Machine Learning Research (PMLR) Vol. 234, & in Conference on Parsimony and Learning (CPAL) , 2024 (Oral) abstract / project page / paper Unsupervised deep metric learning (UDML) focuses on learning a semantic representation space using only unlabeled data. This challenging problem requires accurately estimating the similarity between data points, which is used to supervise a deep network. For this purpose, we propose to model the high-dimensional data manifold using a piecewise-linear approximation, with each low-dimensional linear piece approximating the data manifold in a small neighborhood of a point. These neighborhoods are used to estimate similarity between data points. We empirically show that this similarity estimate correlates better with the ground truth than the similarity estimates of current state-of-the-art techniques. We also show that proxies, commonly used in supervised metric learning, can be used to model the piecewise-linear manifold in an unsupervised setting, helping improve performance. Our method outperforms existing unsupervised metric learning approaches on standard zero-shot image retrieval benchmarks. |
|
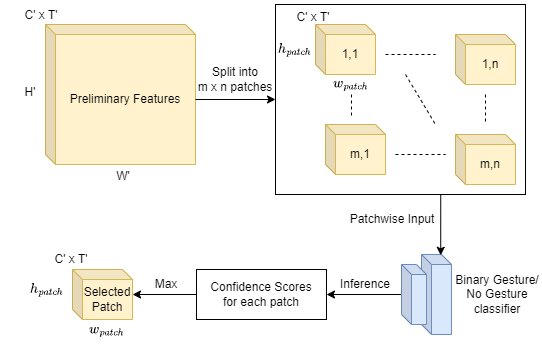
Long-Distance Gesture Recognition using Dynamic Neural NetworksShubhang Bhatnagar, Sharath Gopal , Narendra Ahuja , Liu Ren International Conference on Intelligent Robots and Systems (IROS) , 2023 abstract / project page / paper / arxiv Gestures form an important medium of communication between humans and machines. An overwhelming majority of existing gesture recognition methods are tailored to a scenario where humans and machines are located very close to each other. This short-distance assumption does not hold true for several types of interactions, for example gesture-based interactions with a floor cleaning robot or with a drone. Methods made for short-distance recognition are unable to perform well on long-distance recognition due to gestures occupying only a small portion of the input data. Their performance is especially worse in resource constrained settings where they are not able to effectively focus their limited compute on the gesturing subject. We propose a novel, accurate and efficient method for the recognition of gestures from longer distances. It uses a dynamic neural network to select features from gesturecontaining spatial regions of the input sensor data for further processing. This helps the network focus on features important for gesture recognition while discarding background features early on, thus making it more compute efficient compared to other techniques. We demonstrate the performance of our method on the LD-ConGR long-distance dataset where it outperforms previous state-of-the-art methods on recognition accuracy and compute efficiency. |
|
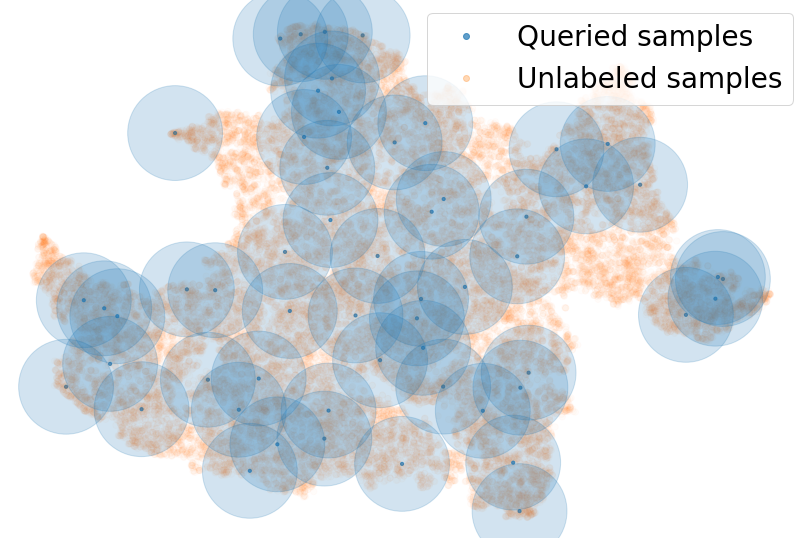
PAL: Pretext based Active LearningShubhang Bhatnagar, Sachin Goyal, Darshan Tank, Amit Sethi British Machine Vision Conference (BMVC), 2021 abstract / project page / paper / code The goal of pool-based active learning is to judiciously select a fixed-sized subset of unlabeled samples from a pool to query an oracle for their labels, in order to maximize the accuracy of a supervised learner. However, the unsaid requirement that the oracle should always assign correct labels is unreasonable for most situations. We propose an active learning technique for deep neural networks that is more robust to mislabeling than the previously proposed techniques. Previous techniques rely on the task network itself to estimate the novelty of the unlabeled samples, but learning the task (generalization) and selecting samples (out-of-distribution detection) can be conflicting goals. We use a separate network to score the unlabeled samples for selection. The scoring network relies on self-supervision for modeling the distribution of the labeled samples to reduce the dependency on potentially noisy labels. To counter the paucity of data, we also deploy another head on the scoring network for regularization via multi-task learning and use an unusual self-balancing hybrid scoring function. Furthermore, we divide each query into sub-queries before labeling to ensure that the query has diverse samples. In addition to having a higher tolerance to mislabeling of samples by the oracle, the resultant technique also produces competitive accuracy in the absence of label noise. The technique also handles the introduction of new classes on-the-fly well by temporarily increasing the sampling rate of these classes. We make our code publicly available at https:// github.com/shubhangb97/PAL_pretext_based_active_learning |
|
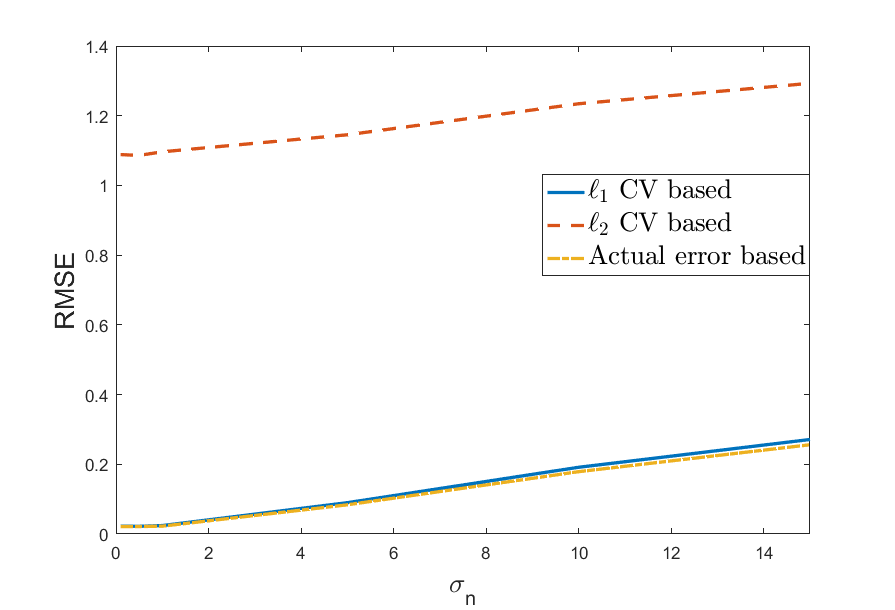
Analyzing Cross Validation in Compressed Sensing with Mixed Gaussian and Impulse Measurement Noise with L1 ErrorsShubhang Bhatnagar*, Chinmay Gurjarpadhye*, Ajit Rajwade European Signal Processing Conference (EUSIPCO), abstract / paper / extended arxiv Compressed sensing (CS) involves sampling signals at rates less than their Nyquist rates and attempting to reconstruct them after sample acquisition. Most such algorithms have parameters, for example the regularization parameter in LASSO, which need to be chosen carefully for optimal performance. These parameters can be chosen based on assumptions on the noise level or signal sparsity, but this knowledge may often be unavailable. In such cases, cross validation (CV) can be used to choose these parameters in a purely data-driven fashion. Previous work analyzing the use of CV in CS has been based on the ℓ2 cross-validation error with Gaussian measurement noise. But it is well known that the ℓ2 error is not robust to impulse noise and provides a poor estimate of the recovery error, failing to choose the best parameter. Here we propose using the ℓ1−CV error which provides substantial performance benefits given impulse measurement noise. Most importantly, we provide a detailed theoretical analysis and error bounds for the use of ℓ1−CV error in CS reconstruction. We show that with high probability, choosing the parameter that yields the minimum ℓ1−CV error is equivalent to choosing the minimum recovery error (which is not observable in practice). To our best knowledge, this is the first paper which theoretically analyzes ℓ1 -based CV in CS. |
|
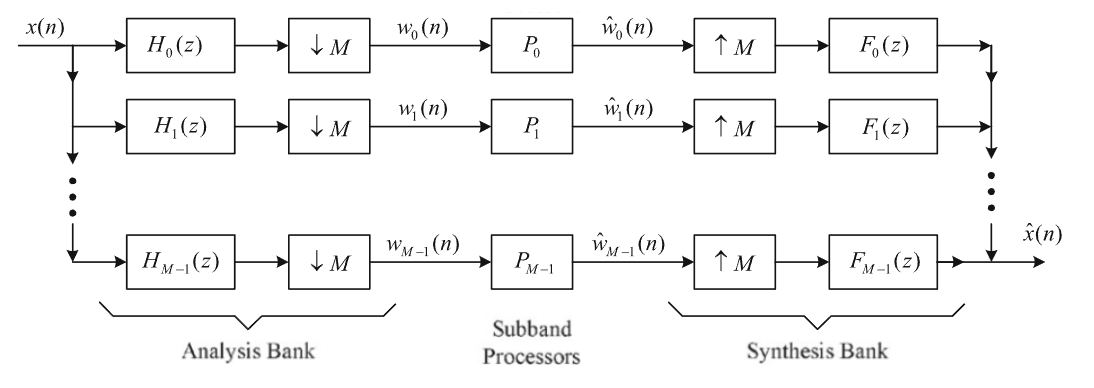
Insights on coding gain and its properties for principal component filter banksPrasad Chaphekar, Aniket Bhatia,Shubhang Bhatnagar, Abhiraj Kanse, Ashish V Vanmali, Vikram M Gadre Sādhanā , Journal of the Indian Academy of Sciences, 2023 abstract / paper Principal Component Filter Bank (PCFB) is considered optimal in terms of coding gain for specificconditions. P P Vaidyanathan stated that coding gain does not necessarily always increase with the increase inthe number of bands. However, very few attempts are made in the literature to go beyond the confines of work done by P P Vaidyanathan. We present analytic proofs for the monotonicity of specific shapes of PSDs. This papers also derives properties of coding gain of PCFBs, which brings the new insights on the coding gain of Principal Component Filter Banks. |

|
QR Code Denoising using Parallel Hopfield NetworksShubhang Bhatnagar*, Ishan Bhatnagar* Arxiv , 2018 abstract / arxiv We propose a novel algorithm for using Hopfield networks to denoise QR codes. Hopfield networks have mostly been used as a noise tolerant memory or to solve difficult combinatorial problems. One of the major drawbacks in their use in noise tolerant associative memory is their low capacity of storage, scaling only linearly with the number of nodes in the network. A larger capacity therefore requires a larger number of nodes, thereby reducing the speed of convergence of the network in addition to increasing hardware costs for acquiring more precise data to be fed to a larger number of nodes. Our paper proposes a new algorithm to allow the use of several Hopfield networks in parallel thereby increasing the cumulative storage capacity of the system many times as compared to a single Hopfield network. Our algorithm would also be much faster than a larger single Hopfield network with the same total capacity. This enables their use in applications like denoising QR codes, which we have demonstrated in our paper. We then test our network on a large set of QR code images with different types of noise and demonstrate that such a system of Hopfield networks can be used to denoise and recognize QR codes in real time. |
|
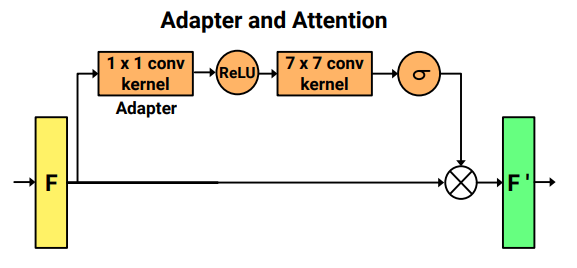
Memory Efficient Adaptive Attention For Multiple Domain LearningHimanshu Pradeep Aswani, Abhiraj Sunil Kanse, Shubhang Bhatnagar, Amit Sethi Arxiv , 2021 abstract / arxiv We propose a novel algorithm for using Hopfield networks to denoise QR codes. Hopfield networks have mostly been used as a noise tolerant memory or to solve difficult combinatorial problems. One of the major drawbacks in their use in noise tolerant associative memory is their low capacity of storage, scaling only linearly with the number of nodes in the network. A larger capacity therefore requires a larger number of nodes, thereby reducing the speed of convergence of the network in addition to increasing hardware costs for acquiring more precise data to be fed to a larger number of nodes. Our paper proposes a new algorithm to allow the use of several Hopfield networks in parallel thereby increasing the cumulative storage capacity of the system many times as compared to a single Hopfield network. Our algorithm would also be much faster than a larger single Hopfield network with the same total capacity. This enables their use in applications like denoising QR codes, which we have demonstrated in our paper. We then test our network on a large set of QR code images with different types of noise and demonstrate that such a system of Hopfield networks can be used to denoise and recognize QR codes in real time. |
Template: this |